
[Kubernetes] Control Plane의 etcd
etcd 란?
Kubernetes는 기반 스토리지(backing storage)로 etcd를 사용하고 있고, 모든 데이터가 etcd에 보관된다. 예를 들어, 클러스터에 어떤 노드가 몇 개나 있고 어떤 파드가 어떤 노드에서 동작하고 있는지가 etcd에 기록된다. 만약 동작 중인 클러스터의 etcd 데이터베이스가 유실된다면 컨테이너뿐만 아니라 클러스터가 사용하는 모든 리소스가 미아가 되어버린다. etcd는 고가용성과 데이터의 일관성을 보장하기 위해 일반적으로 3개 이상의 etcd 인스턴스로 클러스터를 구성한다.
etcd는 RSM(Replicated state machine)
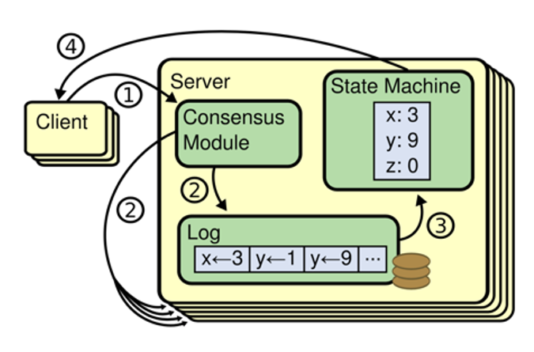
분산 컴퓨팅 환경에서 서버가 몇 개 다운되어도 잘 동작하는 시스템을 만들고자 할 때 선택하는 방법의 하나로, State Machine Replication이 있다. 이는 똑같은 데이터를 여러 서버에 계속하여 복제하는 것이며, 이 방법으로 사용하는 머신을 RSM이라고 한다. RSM은 위 그림과 같이 command가 들어있는 log 단위로 데이터를 처리한다. 데이터의 write를 log append라 부르며, 머신은 받은 log를 순서대로 처리한다. 이 때, 데이터 복제 과정에서 문제가 발생할 수 있기 때문에 etcd에서는 데이터 일관성을 보장하고자 합의 알고리즘을 사용한다.
etcd의 Raft 합의 알고리즘을 통한 일관성 유지 메커니즘
etcd는 고가용성을 위해 여러 인스턴스로 구성하는 것이 일반적이다. 이 때 데이터 일관성을 보장하기 위해 리더를 선출하고 팔로워들에게 데이터를 복제한 후 합의 과정을 거친다.
여기에 사용되는 알고리즘이 Raft 합의 알고리즘이다. Raft 합의 알고리즘은 아래와 같이 동작한다.
1) 리더 선출:
etcd 클러스터는 리더 노드를 중심으로 동작한다. 리더 노드는 데이터를 쓰거나 수정하는 유일한 권한을 가지며, 다른 노드들은 팔로워(follower)로 동작한다.
리더가 변경 사항을 클라이언트로부터 받으면, 다른 팔로워 노드들에 이 변경 사항을 전파하고 이를 동기화한다.
리더는 주기적으로 팔로워들에게 Heartbeat 메시지를 보내 자신이 아직 리더임을 확인시킨다.
2) 로그 복제:
리더는 모든 변경 사항(쓰기 요청)을 로그(log)로 기록하며, 이를 다수의 팔로워 노드에 복제한다.
리더가 변경 사항을 팔로워에게 전파할 때, 팔로워는 로그 항목을 저장하고 이를 리더에게 응답한다.
리더는 다수의 팔로워(과반수)가 변경 사항을 성공적으로 기록했다고 응답할 때만, 해당 변경 사항을 커밋하여 클러스터에 반영한다.
3) 과반수 합의:
etcd는 과반수 합의(majority consensus)를 통해 데이터 일관성을 유지한다. 즉, 변경 사항이 클러스터의 절반 이상의 노드에 적용되면, 변경 사항이 커밋되었다고 간주한다.
이를 통해 일부 노드에 장애가 발생하더라도, 과반수가 동작 중이라면 데이터가 일관되게 유지될 수 있다.
4) 리더 재선출:
리더 노드가 다운되거나 네트워크 문제로 응답하지 않으면, etcd 클러스터는 새로운 리더를 선출한다.
팔로워 노드 중 하나가 새로운 리더로 선출되며, 그 이후의 변경 사항은 새로운 리더를 통해 처리된다.
리더가 변경되어도, 로그 복제에 의해 일관성이 유지된다.
etcd는 두 가지 읽기 모드
etcd의 합의 알고리즘에 따라 리더 노드에서만 읽기를 처리할 수도 있지만, 경우에 따라 팔로워 노드에서 읽기를 허용하여 부하를 분산할 수도 있다. 이로 인해 데이터 불일치 문제가 생길 수 있기 때문에 애플리케이션 동작에 문제가 없을지 잘 검토하고 선택해야한다.
1) 선형적 일관성(Linearizability) - 강한 일관성 모드
이 모드는 리더 노드에서만 읽기를 처리하며, 데이터를 요청한 클라이언트에게 항상 최신의 데이터를 반환한다.
리더 노드가 변경 사항을 모두 커밋하고, 그 데이터를 읽기 요청에 반영하므로, 최신 데이터를 보장한다.
일관성을 가장 강하게 유지하지만, 모든 읽기 요청이 리더에게 집중되므로 리더의 부하가 증가할 수 있다.
2) 일관성 읽기(Consistent Read) - 약한 일관성 모드
팔로워 노드에서 읽기를 허용하여, 읽기 부하를 분산할 수 있다.
하지만 이 경우, 일관성이 약해질 수 있는 상황이 발생할 수 있다. 예를 들어, 팔로워 노드가 최신 데이터를 복제받기 전에 읽기 요청을 처리할 경우, 약간의 지연이 있는 데이터를 반환할 수 있다.
이를 통해 부하를 분산할 수 있지만, 최신성이 약간 떨어질 수 있다.
여러 노드를 운영하는 이유
etcd를 여러 노드로 운영하는 이유는 아래와 같이 정리해볼 수 있다.
1) 장애 대비:
etcd 클러스터는 다수의 노드를 구성하여 고가용성을 보장한다. 리더 노드가 다운되면, 남은 노드들 중 하나가 새로운 리더로 선출되므로 서비스 중단 없이 지속적으로 동작할 수 있다.
리더가 되지 않은 팔로워 노드도 중요한 역할을 하며, 노드 중 과반수가 동작하면 시스템은 정상적으로 유지된다.
2) 읽기 부하 분산:
읽기 요청을 팔로워 노드에서 처리할 수 있는 일관성 읽기 모드를 사용하면, 리더 노드에 집중되는 읽기 요청을 분산시킬 수 있다. 이를 통해 부하 분산이 가능해지고, 시스템 성능을 높일 수 있다.
3) 데이터 복제 및 신뢰성:
리더는 모든 데이터를 팔로워 노드에 복제한다. 이 과정에서 데이터 일관성이 보장되며, 노드에 장애가 발생하더라도 데이터 손실 없이 복구할 수 있다.
리더 노드의 과도한 부하를 해결하기 위한 아키텍처적 접근법
1) 리드 리플리카(Read Replica) 사용: 리더 노드의 복제본을 여러 개 두고, 이를 통해 읽기 요청을 분산 처리할 수 있다. 리드 리플리카를 통해 읽기 요청 부하를 분산시키면서도 일정 수준의 일관성을 유지할 수 있다.
2) 캐싱: 읽기 요청이 자주 발생하는 데이터에 대해 캐시 시스템(예: Redis, Memcached)을 사용하여 리더 노드에 대한 부하를 줄일 수 있다. 자주 변하지 않는 데이터나 읽기 요청이 많은 데이터는 캐시에 저장하여, 데이터베이스에 접근하지 않고 빠르게 처리할 수 있다.
3) 리더-팔로워 아키텍처의 최적화: 리더가 처리할 수 없는 과도한 요청이 몰리는 경우, 일관성이 덜 중요한 읽기 요청을 팔로워 노드로 분산하는 전략을 적극 활용할 수 있다.
4) Sharding: 데이터베이스를 여러 개의 샤드로 나누어 각 샤드별로 리더 노드를 설정하여 부하를 분산하는 방식입니다. 이를 통해 특정 노드에 부하가 집중되지 않도록 할 수 있다.
5) Auto-scaling:etcd 클러스터의 성능을 지속적으로 모니터링하고, 리더 노드가 과부하 상태에 빠지면, 클러스터 자체를 자동 확장하는 방식을 도입할 수 있다.
Reference
https://tech.kakao.com/posts/484