
[Database] Connection Pool이란 무엇일까?
Connection Pool 이란?
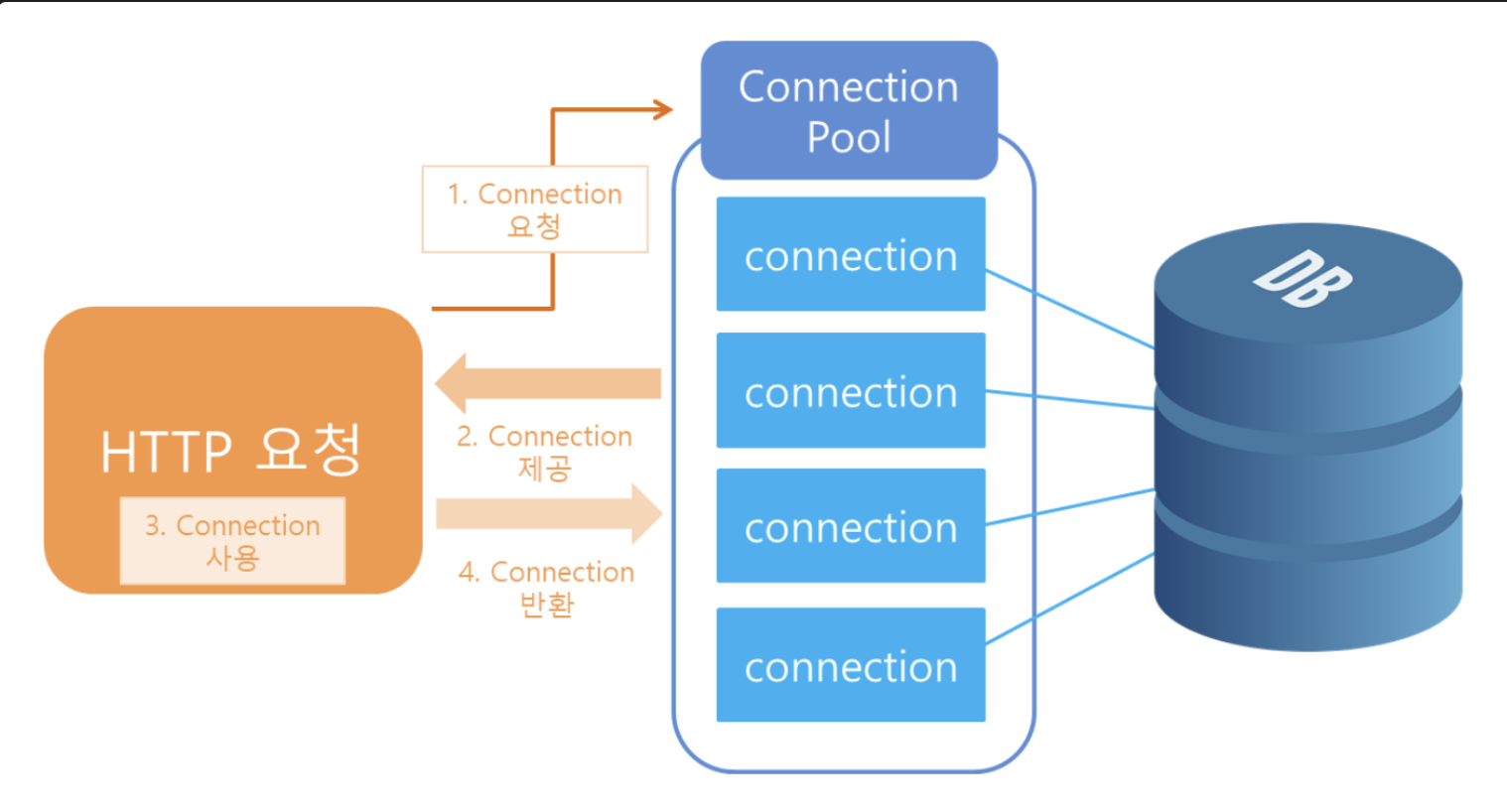
웹 애플리케이션 서버(WAS)가 실행되면서 DB와 미리 connection(연결)을 해놓은 객체들을 pool에 저장해두었다가 클라이언트 요청이 오면 connection을 빌려주고, 처리가 끝나면 다시 connection을 반납받아 pool에 저장하는 방식이다.
Connection 객체를 생성하는 과정을 한 번 살펴보자!
- 애플리케이션에서 DB 드라이버를 통해 커넥션을 조회한다.
- DB 드라이버는 DB와 TCP/IP 커넥션을 연결한다. (3 way handshake와 같은 네트워크 연결 동작 발생)
- DB 드라이버는 TCP/IP 커넥션이 연결되면 아이디와 패스워드, 기타 부가 정보를 DB에 전달한다.
- DB는 아이디, 패스워드를 통해 내부 인증을 거친 후 내부에 DB를 생성한다.
- DB는 커넥션 생성이 완료되었다는 응답을 보낸다.
- DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다. -> DB 연결할 때마다 Connection 객체를 새로 만드는 것은 비용이 많이 들며, 굉장히 비효율적이다.
이러한 문제를 해결하기 위해 애플리케이션 로딩 시점에 Connection 객체를 미리 생성하고, 애플리케이션에서 데이터베이스에 연결이 필요할 경우 미리 준비된 Connection 객체를 사용하여 애플리케이션의 성능을 향상하는 커넥션 풀 (Connection Pool)이 등장하게 된다.
- Connection Pool은 WAS 내부에 내장되어 존재하는 경우가 많다.
- 하지만 경우에 따라, Connection Pool은 별도의 서버나 서비스로 구성될 수 있다. 이러한 구성은 대규모 시스템이나 분산 시스템에서 볼 수 있다. 여기서 Connection Pool은 중앙 집중식 서비스로 작동하며, 여러 애플리케이션에서 공유할 수 있다.
커넥션 풀(DBCP)의 유의 사항
동시 접속자가 많을 경우
너무 많은 DB 접근이 발생할 경우에는 커넥션은 한정되어 있기 때문에 쓸 수 있는 커넥션이 발납될 때까지 기다려야 한다. 너무 많은 커넥션을 생성할 시에는 커넥션 또한 객체이므로 많은 메모리를 차지하게 되고, 프로그램의 성능을 떨어뜨리는 원인이 된다. 즉, WAS에서 커넥션 풀을 크게 설정하면 메모리 소모가 큰 대신 많은 사용자가 대기 시간이 줄어 들고, 반대로 커넥션 풀을 작게 설정하면 그 만큼 대기 시간이 길어진다. 따라서 사용량에 따라 적정량의 커넥션 객체를 생성해 두어야 한다.
Connection Pool이 커지면 성능은 무조건 좋아질까?
그렇지 않다. Connection의 주체는 Thread이므로 Thread와 함께 고려해야 한다.
- Thread Pool 크기 < Connection Pool 크기
- Thread Pool에서 트랜잭션을 처리하는 Thread가 사용하는 Connection 외에 남는 Connection은 실질적으로 메모리 공간만 차지하게 된다.
- Thread Pool 크기와 Connection Pool 모두 크기 증가
- Thread 증가로 인해 더 많은 Context Switching이 발생한다.
- Disk 경합 측면에서 성능 한계가 발생한다.
- 데이터베이스는 하드 디스크 하나 당 하나의 I/O를 처리하므로 블로킹이 발생한다.
- 즉, 특정 시점부터는 성능적인 증가가 Disk 병목으로 인해 미비해진다.
따라서 데이터베이스 입자에서 Connection은 Thread와 어느 정도 일치한다고 볼 수 있다. Connection이 많다는 의미는 데이터베이스 서버가 Thread를 많이 사용한다는 것을 의미하고, 이에 따라 Context Switching으로 인한 오버헤드가 더 많이 발생하기 때문에 Connection Pool을 아무리 늘리더라도 성능적인 한계가 존재한다.
Connection Pool의 크기는 얼마나 적절할까?
- Hikari CP의 공식 문서에 의하면,
1 connections = ((core_count) * 2) + effective_spindle_count)로 정의하고 있다. - core_count는 현재 사용하는 서버 환경에서의 CPU 개수를 의미한다.
core_count * 2를 하는 이유는 Context Switching 및 Disk I/O와 관련이 있다.- Context Switching으로 인한 오버헤드를 고려하더라도 데이터베이스에서 Disk I/O(혹은 DRAM이 처리하는 속도)보다 CPU 속도가 월등히 빠르다.
- 그러므로, Thread가 Disk와 같은 작업에서 블로킹되는 시간에 다른 Thread의 작업을 처리할 수 있는 여유가 생기고, 여유 정도에 따라 멀티 스레드 작업을 수행할 수 있게 된다. Hikari CP가 제시한 공식에서는 계수를 2로 선정하여 Thread 개수를 지정하였다.
- effective_spindle_count는 기본적으로 DB 서버가 관리할 수 있는 동시 I/O 요청 수이다.
- 하드 디스크 하나는 spindle 하나를 갖는다.
- 디스크가 16개 있는 경우, 시스템은 동시에 16개의 I/O 요청을 처리할 수 있다.
References
https://shuu.tistory.com/130